
Hello All,
Many queries attribute good percentage of CPU time to table scan, so with making scan improvement, many queries will get performance improvement. Currently we focus on table scan optimization for tables stored in ORC format (but should be possible to extend to other data formats also).
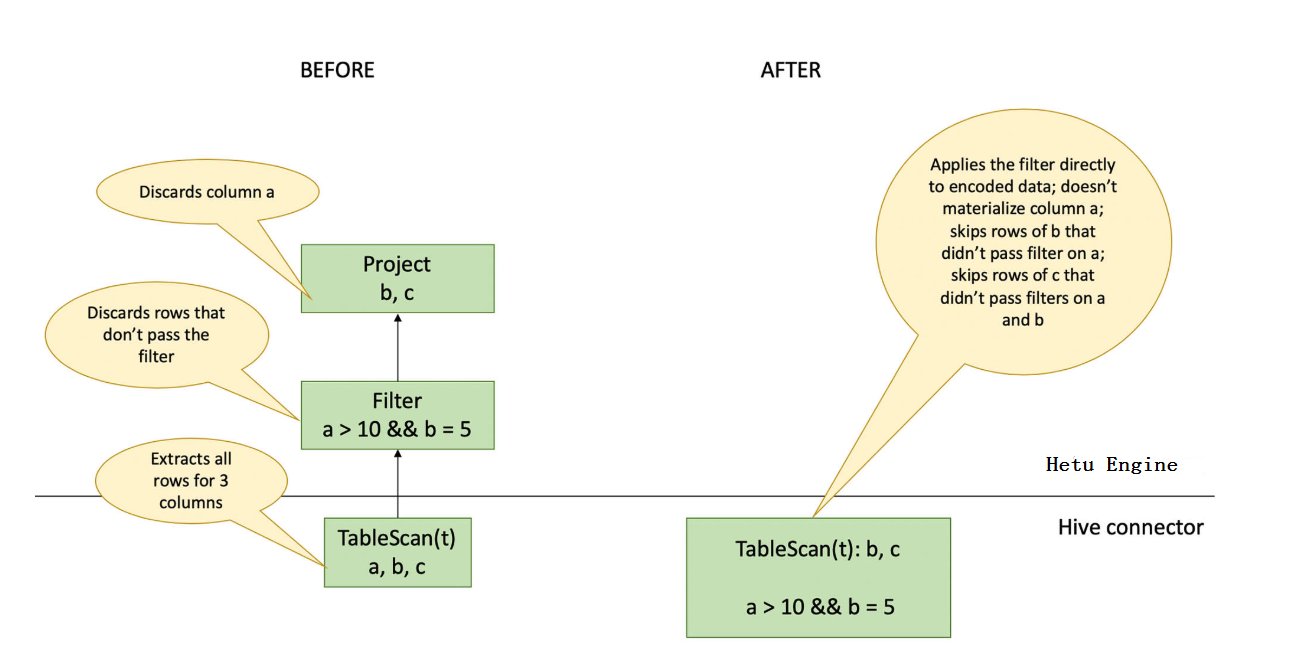
Overall approach for filter pushdown can be depicted as in the below picture. As can be seen, in the new approach (right side), filter evaluation has been pushed to the HIVE connector from the engine. [image: image.png]
Below is a list of ideas to optimize table scan by reducing CPU time. 1. *Filter Pushdown* (Only deterministic filter e.g. id>10, id in (10,20) etc): This optimization is required to push the filter from engine to hive connector so that only filtered rows/columns get returned back to the engine layer. 2. *Efficient Row Skipping*: Currently if a filter on one column matches only for a small set of rows, then still we read all values in subsequent columns which are part of the query and immediately discard them. This waste CPU cycle unnecessarily. This can be optimized to read only rows for next columns which matched as part of the previous column. 3. *Avoid unwanted Columns*: Using this approach, the connector will return only columns required to project and not the column which was just used for the filter. 4. *Filter Re-ordering (Part-1)*: Considering the "Efficient Row Skipping", it is always beneficial to process columns with filter first which results in the least number of rows, so that further column processing needs to process only a relatively small number of rows. As part of this re-ordering will be done in such a way that the first column with filter will be processed first and then column without filter. But with-in the multiple column with filter ordering will be done later.
In the first proposal, We would like to propose a design for the all the above optimization idea. Major changes required in HIVE connector to process filter along with some changes in optimizer to push filter down to connector. 1. HIVE Connector (ORC format) - Rajeev Rastogi 2. Optimizer - Nitin Kashyap.
We will require a session configuration variable to enable/disable this feature. By default it will be disabled. We propose to have a configuration variable named as "*orc_predicate_pushdown_enabled*" for the same. But we can also discuss naming it as "*experimental_orc_predicate_pushdown_enabled*" till we see all TODO items finished and see everything working fine.
Attached is the design document. Please let us know if any comments/suggestions.
Once the first part is done, then it will open up opportunities for further optimization, some of them are as mentioned below:
5. *Not-deterministic Filter Pushdown (e.g. id1+id2 > 10 etc)*: As part of this non-deterministic filter will be pushed down to the connector layer and the same will be processed in the connector itself (like function processing). 6. *Filter Re-ordering (Part-2): *As part of this, re-ordering among multiple columns with a filter will be done. We may make use of stats (or type of filter) here to see which filter may return how many rows and then accordingly reorder it. 7. *Sub-field Pruning*: Hetu supports structural complex data-type e.g. Map, Array, List. In the current approach HIVE connector returns a whole map corresponding to a column and row, which may include many keys but the application might be interested in only one key. So here the optimization idea is to prune those unwanted keys and return whatever really wanted by the user. E.g. query "*SELECT ISDCODE('INDIA') FROM CITIZEN*", connector will no longer return ISDCODE corresponding to other countries stored in this row column. 8. *Multi-Column OR condition*: Handling of predicate OR condition on multiple columns. 9. In addition to these optimizations, there are some *TODO items in the design document*, which we can discuss to decide if it can be taken up after the first phase.
{kind=link}
-
 Rajeev Rastogi
Rajeev Rastogi